Information Gain (IG) is critical in machine learning and decision tree algorithms, particularly in data classification and 𝐟𝐞𝐚𝐭𝐮𝐫𝐞 𝐬𝐞𝐥𝐞𝐜𝐭𝐢𝐨𝐧.
Information Gain
Information Gain is a concept used in the field of machine learning and decision trees to measure the effectiveness of an attribute in classifying a dataset. It is commonly employed in the construction of decision trees for classification tasks. The Information Gain of an attribute quantifies the reduction in uncertainty about the target variable (class) when the dataset is split based on that attribute. Higher Information Gain indicates that the attribute is more informative in terms of classifying the data.
In the context of decision trees, Information Gain is often used to determine the best attribute for splitting the data at each node, leading to a more effective and accurate classification model.
It is pivotal in determining the optimal way to split data in decision trees, enabling more effective and accurate decision-making processes.
The primary objective of decision trees is to create a model that can classify data points into different categories or classes based on their features.
To accomplish this, decision trees recursively split the dataset into subsets, aiming to maximize each resulting subset’s homogeneity (purity) concerning the target class variable.
IG is a metric to quantify the reduction in uncertainty or randomness in the data after a particular split.
The Algorithmic Flow

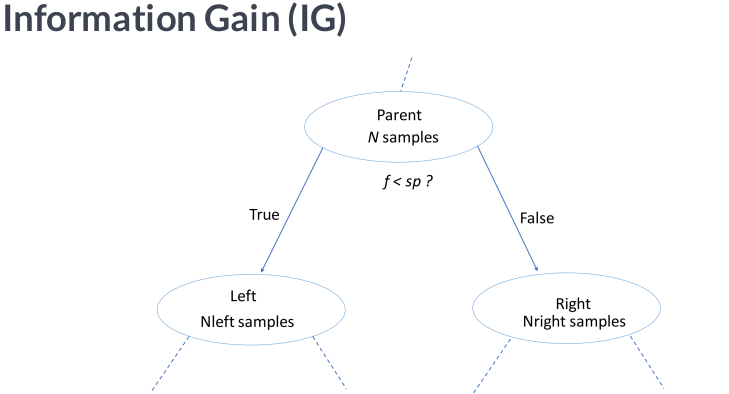
▸Before any splits, the impurity of the entire dataset is measured using metrics like 𝒆𝒏𝒕𝒓𝒐𝒑𝒚 or 𝑮𝒊𝒏𝒊 𝒊𝒎𝒑𝒖𝒓𝒊𝒕𝒚. Higher impurities indicate a mix of different classes within the dataset.
▸Decision trees evaluate various features and their thresholds to determine the most informative split. The goal is to find the feature and threshold that best separates the data into subsets with lower impurities.
▸After the split, IG is calculated to measure the reduction in impurity:
𝘐𝘎 = 𝘐𝘯𝘪𝘵𝘪𝘢𝘭 𝘐𝘮𝘱𝘶𝘳𝘪𝘵𝘺 – 𝘞𝘦𝘪𝘨𝘩𝘵𝘦𝘥 𝘈𝘷𝘦𝘳𝘢𝘨𝘦 𝘰𝘧 𝘚𝘶𝘣𝘴𝘦𝘵𝘴’ 𝘐𝘮𝘱𝘶𝘳𝘪𝘵𝘪𝘦𝘴
The proportion of data weights each subset’s impurity points relative to the original dataset the weighted average accounts for the size of each subset.
▸Decision trees repeat this process for all available features and thresholds, calculating IG for each possible split. The split with the highest IG is selected as the best choice.
▸Splitting and calculating IG is repeated recursively for each subset until a predefined stopping criterion is met. This leads to the creation of a hierarchical decision tree.
IG helps decision trees make intelligent decisions about how to divide the data by quantifying the reduction in uncertainty that each potential split offers.
High IG implies that a split leads to more homogenous subsets, making it a favorable choice for building an accurate classification model.